今天的影片內容為介紹selenium的webdriver物件用來尋找網頁元素的方法
其實跟BeautifulSoup模組中find()以及find_all()是差不多的呦~
有了前面的基礎一定很快就能學會!

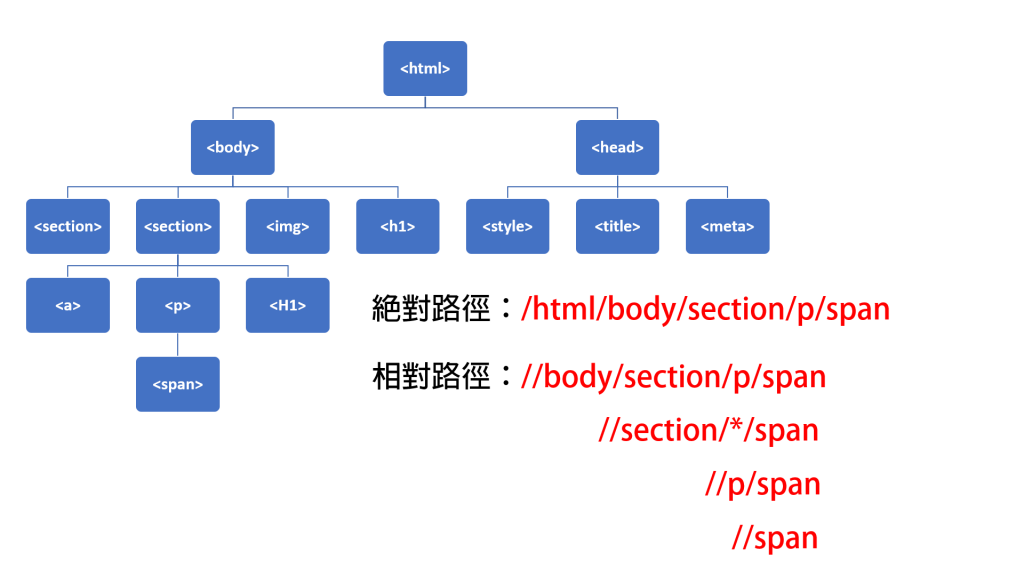
以下為絕對路徑與相對路徑的概念圖
以下為ChroPath的連結
https://chrome.google.com/webstore/detail/chropath/ljngjbnaijcbncmcnjfhigebomdlkcjo/related
以下為影片中有使用到的程式碼
<!doctype html>
<!-- 請將此檔案儲存成bs4_HTML.html -->
<html lang="zh-tw">
<head>
<meta charset="utf-8">
<title>水母</title>
<style>
section.section1 {background-color:#AAFFEE;} /*薄荷綠*/
h1#title {background-color:#CCCCFF;} /*淡紫色*/
h1#content1 {color:#227700;} /*深綠色*/
h1#content2 {color:#7700BB;} /*深紫色*/
span {color:red;}
</style>
</head>
<body>
<h1 id="title">水母的天敵</h1>
<img src="DSC_0394.jpg" alt="於海生館拍攝的水母" height="300" width="450">
<section class="section1">
<h1 id="content1">海龜</h1>
<p>捕食水母為生,海龜除了<span>眼睛</span>外,身體其他部分都可以抵抗水母的毒性,牠們在捕食水母時會閉上眼睛。</p>
<a href="https://zh.wikipedia.org/wiki/%E6%B5%B7%E9%BE%9F">維基百科海龜連結</a>
</section>
<section class="section1">
<h1 id="content2">紫螺</h1>
<p>分布在熱帶太平洋溫暖的水域,愛吃漂浮在水面的水母。</p>
<a href="https://zh.wikipedia.org/wiki/%E7%B4%AB%E8%9E%BA">維基百科紫螺連結</a>
</section>
</body>
</html>
#開啟電腦中的檔案
#請將C:\\spider\\修改為chromedriver.exe在您電腦中的路徑
#請將C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改為bs4_HTML.html在您電腦中的路徑
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
print('瀏覽器名稱:', browser.name)
print('網頁網址:', browser.current_url)
print('網頁標題:', browser.title)
print('網頁原始碼:\n', browser.page_source)
#find_element(s)_by_XX
#請將C:\\spider\\修改為chromedriver.exe在您電腦中的路徑
#請將C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改為bs4_HTML.html在您電腦中的路徑
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
tag_1 = browser.find_element_by_id('title') #回傳第一個id相符的元素
print("回傳第一個id為title的元素內容:\n", tag_1.text)
print("="*100)
tag_2 = browser.find_element_by_class_name('section1') #回傳第一個相符class的元素
print("回傳第一個class為section1的元素內容:\n", tag_2.text)
tag_3 = browser.find_elements_by_class_name('section1') #回傳所有相符class的元素,以串列傳回
print("回傳所有class為section1的元素內容:\n", tag_3)
for tag in tag_3:
print(tag.text)
print("="*100)
tag_4 = browser.find_element_by_css_selector('h1') #回傳第一個相符CSS選擇器的元素
print("回傳第一個CSS選擇器為h1的元素內容:\n", tag_4.text)
tag_5 = browser.find_elements_by_css_selector('h1') #回傳所有相符的CSS選擇器的元素,以串列傳回
print("回傳所有CSS選擇器為h1的元素內容:")
for tag in tag_5:
print(tag.text)
#find_element(s)_by_XX
#請將C:\\spider\\修改為chromedriver.exe在您電腦中的路徑
#請將C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改為bs4_HTML.html在您電腦中的路徑
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
tag_6 = browser.find_element_by_partial_link_text('海龜') #回傳第一個含有XX內容的<a>元素
print("回傳第一個含有「海龜」內容的<a>元素內容:\n", tag_6.text)
tag_7 = browser.find_elements_by_partial_link_text('維基百科') #回傳所有含有XX內容的<a>元素
print("回傳所有含有「維基百科」內容的<a>元素內容:")
for tag in tag_7:
print(tag.text)
print("="*100)
tag_8 = browser.find_element_by_link_text('維基百科海龜連結') #回傳第一個含有XX內容的<a>元素(要完全相符)
print("回傳第一個含有「維基百科海龜連結」內容的<a>元素內容:\n", tag_8.text)
tag_9 = browser.find_elements_by_link_text('維基百科海龜連結') #回傳所有含有XX內容的<a>元素(要完全相符)
print("回傳所有含有「維基百科海龜連結」內容的<a>元素內容:")
for tag in tag_9:
print(tag.text)
print("="*100)
tag_10 = browser.find_element_by_tag_name('span') #回傳第一個相符的元素(不區分大小寫)
print("回傳第一個<span>元素的內容:\n", tag_10.text)
tag_11 = browser.find_elements_by_tag_name('p') #回傳所有相符的元素(不區分大小寫)
print("回傳所有<p>元素的內容:")
for tag in tag_11:
print(tag.text)
#XPath
#請將C:\\spider\\修改為chromedriver.exe在您電腦中的路徑
#請將C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改為bs4_HTML.html在您電腦中的路徑
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
X_1 = browser.find_element_by_xpath('/html/body/section/p/span')
print(X_1.text)
print("="*100)
X_2 = browser.find_element_by_xpath('//body/section/p/span')
print(X_2.text)
print("="*100)
X_3 = browser.find_element_by_xpath('//section/*/span')
print(X_3.text)
print("="*100)
X_4 = browser.find_element_by_xpath('//p/span')
print(X_4.text)
print("="*100)
X_5 = browser.find_element_by_xpath('//span')
print(X_5.text)
#XPath
#請將C:\\spider\\修改為chromedriver.exe在您電腦中的路徑
#請將C:\\Users\\ASUS\\Desktop\\bs4_HTML\\修改為bs4_HTML.html在您電腦中的路徑
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'C:\\Users\\ASUS\\Desktop\\bs4_HTML\\bs4_HTML.html'
browser.get(url)
X_1 = browser.find_element_by_xpath('//section')
print(X_1.text)
print("="*100)
X_2 = browser.find_element_by_xpath('//section[1]')
print(X_1.text)
print("="*100)
X_3 = browser.find_element_by_xpath('//section[2]')
print(X_3.text)
#利用XPath尋找台彩網頁雙贏彩區塊
#請將C:\\spider\\修改為chromedriver.exe在您電腦中的路徑
from selenium import webdriver
dirverPath = 'C:\\spider\\chromedriver.exe'
browser = webdriver.Chrome(executable_path = dirverPath)
url = 'https://www.taiwanlottery.com.tw/index_new.aspx'
browser.get(url)
XPath = browser.find_element_by_xpath("//body/form[@id='form1']/div[@id='wrapper_overflow']/div[@id='rightdown']/div[3]")
print(XPath.text)
本篇影片及程式碼僅提供研究使用,請勿大量惡意地爬取資料造成對方網頁的負擔呦!
如果在影片中有說得不太清楚或錯誤的地方,歡迎留言告訴我,謝謝您的指教。

